
Rook: New Winds in the v1.1 release

This is a cross post of an older post from The Cloud Report, be sure to checkout the The Cloud Report website.
Thanks to them for allowing me to write and publish the post on their blog!
Preface
Rook is a storage orchestrator for Kubernetes using the operator pattern.
That means that Rook can run, e.g., Ceph, EdgeFS, Yugabyte and other persistence providers in a Kubernetes cluster.
This allows applications to create, e.g., a YBCluster object to get a YugabyteDB cluster to provide persistence for your applications in Kubernetes.
Be sure to check out Rook's website Rook.io for more information.
Numbers
The Rook project is continuously growing, more contributors, more Twitter followers and the growing Slack member count. The following are the numbers from the official Rook v1.1 release blog post:
- 5K to 6K+ Github stars
- 150 to 196 Contributors
- 40M to 74M+ Container downloads
- 3050 to 3700+ Twitter followers
- 1610 to 2200+ Slack members
Those numbers are awesome for the storage backends and Rook itself!
It is good to see the project grow in numbers, but also mature further in regards to governance, project charter and CNCF project graduation in the future. With each release Rook is getting more boring. This is good, as especially newly introduced features get faster stable because of that.
New Features and Improvements
Let's dive into some of the most outstanding features and improvements of the latest Rook 1.1 release.
New Storage Provider: Yugabyte DB
In the latest Rook release version 1.1, Yugabyte DB joined the list of storage providers in the Rook project. Bringing the total of storage providers to 7.
Below list contains all current storage providers which are integrated in Rook:
- Cassandra
- Ceph
- CockroachDB
- EdgeFS
- Minio
- NFS
- Yugabyte DB
To show how easy it know is to create a Yugabyte DB cluster in Kubernetes, just look at the code snippet:
apiVersion: yugabytedb.rook.io/v1alpha1
kind: YBCluster
metadata:
name: hello-ybdb-cluster
namespace: rook-yugabytedb
spec:
master:
replicas: 3
volumeClaimTemplate:
[...]
tserver:
replicas: 3
network:
ports:
- name: yb-tserver-ui
port: 9000
- name: yb-tserver-rpc
port: 9100
- name: ycql
port: 9042
- name: yedis
port: 6379
- name: ysql
port: 5433
volumeClaimTemplate:
[...]
Yep, just a few lines of code and the Rook Yugabyte DB operator will take care of creating everything needed for a Yugabyte DB cluster. That is the magic that the Operator Pattern in Kubernetes brings. Applications like that are destined to have an operator with CustomResourceDefinitions to make life easier for the Development and Operations teams in Kubernetes.
One more thing to note is that you can technically run a Rook Ceph or EdgeFS Cluster in your Kubernetes and run, e.g., Yugabyte DB, Minio, and so on, on top of that storage provider.
If you want to know more about Yugabyte DB Rook integration, checkout their blog post Yugabyte DB Blog - Announcing the New Rook Operator for Yugabyte DB.
Ceph
![]()
CSI the new default for Provisioning and Mounting Storage
In previous releases the default was to use the Rook Flexvolume driver for provisioning and mounting of Ceph storage. In comparision with the now default Ceph CSI driver, the Flexvolume is lacking features, like dynamic provisioning of PersistentVolumeClaim for CephFS (filesystem storage).
The Ceph CSI driver brings many improvements and the mentioned dynamic provisioning feature for CephFS PersistentVolumeClaims. There is a lesser used features that is not implemented in the Ceph CSI driver yet, mounting erasure-coded block storage, but the Ceph CSI team is working on implement this feature to bring it on the same level as the Flexvolume.
For the impatient people that want to get the CephFS dynamic provisioning for their cluster and/ or get started with Rook in general, checkout the Rook v1.1 Documentation.
OSDs can now run on PersistentVolumeClaims
Yep, you read that right, Ceph OSDs (data stores) can now run on PersistentVolumeClaims. This finally gives many people an option to reliably run in cloud environments (e.g., Azure, AWS, Google Cloud) with their Rook Ceph cluster setups.
Fun fact: This technically enables one to run a Rook Ceph Cluster on PersistentVolumes from another Rook Ceph cluster.
Let's continue on that fun fact in Rook Ceph in Rook Ceph in Rook Ceph ….
Rook Ceph in Rook Ceph in Rook Ceph …
I will soon be doing an experiment, in which I'll be running a Rook Ceph Cluster on top of another Rook Ceph Cluster. "Wrapping" a Rook Ceph Cluster once in another Rook Ceph Cluster is boring though, so the experiment will be to wrap a Rook Ceph Cluster on top of as many other warpped Rook Ceph Cluster as possible.
EdgeFS
Has accomplished a milestone in the Rook project by being the second storage provider to release their CRDs as stable v1.
That is awesome to see, but not the only big accomplishment for the v1.1 release.
For a general roundup of all that is new in EdgeFS, checkout Kubernetes Rook EdgeFS 1.1 Released - EdgeFS.
Multi homed network
EdgeFS is the first to implement multi (homed) network. Their initial integration efforts are done with Intel's project Multus CNI.
This is thanks to the Google Summer of Code (GSoC) participant @giovanism!
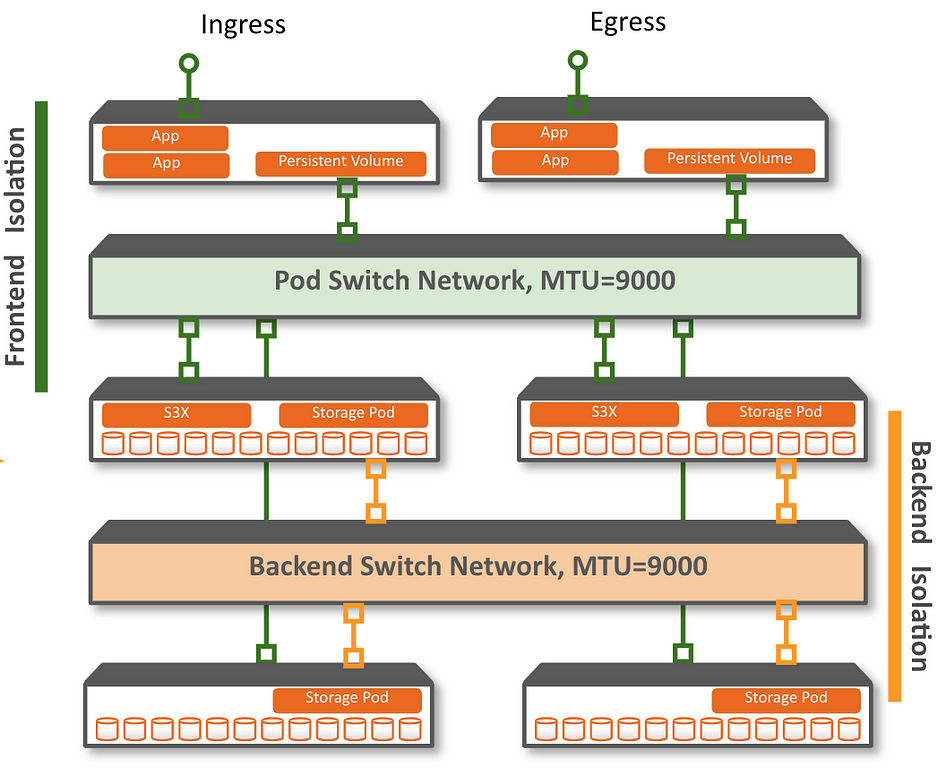 Source: EdgeFS v1.1 Release Blog Post
Source: EdgeFS v1.1 Release Blog Post
In their v1.1 blog post, from which the diagram was taken, contains a performance benchmarks that shows that multi homed network can improve the performance of the storage. Besides the performance improvements, depending on the network setup this can even allow the storage to be more resilient as it would be, e.g., unaffected by application network outages.
This is a huge thing to happen in the Rook project and hopefully soon to be seen to be implemented in the Rook Ceph Cluster CRD as well.
Summary
The Rook project is getting boring. There are still many important things to further work and improve on. One burning topic is disaster recovery, which is pretty much a complex manual process right now. That process just "screams" to be "automated" to a certain aspect, to remove the human factor as much as possible.
Join the in-cluster storage revolution, Rook on!
How to get involved
If you are interested in Rook, don’t hesitate to connect with the Rook community and project using the below ways.
Besides the typical social media channels, Slack and so on, should you attend the KubeCon + CloudNativeCon North America 2019 be sure to visit the CNCF Project Pavilion.
Other articles about Rook
If you are interested in reading other articles about the Rook project, be sure to checkout the following links:
- http://the-report.cloud/rook-more-than-ceph
- http://the-report.cloud/rook-v1-0-adds-support-for-ceph-nautilus-edgefs-and-nfs-operator
- https://blog.rook.io/rook-v1-1-accelerating-storage-providers-5b9e8d5901d8
- https://medium.com/edgefs/kubernetes-rook-edgefs-1-1-released-452799283fce
- https://blog.yugabyte.com/rook-operator-announcement/